
한다 공부
[AI] YOLOv3를 이용한 Object detection (with Colab) 본문
우선 코랩에 대해 알아보자.
코랩이란? Colaboratory의 약자로 Google에서 교육과 과학 연구를 목적으로 개발한 도구이다.
코랩을 이용하면 Python의 다양한 라이브러리를(numpy 등) 활용하여 데이터 분석 및 시각화를 할 수 있다.
또한 코드 몇 줄만으로 이미지 data set 을 가져올 수 있고, 이미지 분류를 학습시킬 수 있다.
코랩을 이용하면 GPU를 무료로 액세스할 수도 있다.
코랩의 구조는 아래와 같다.
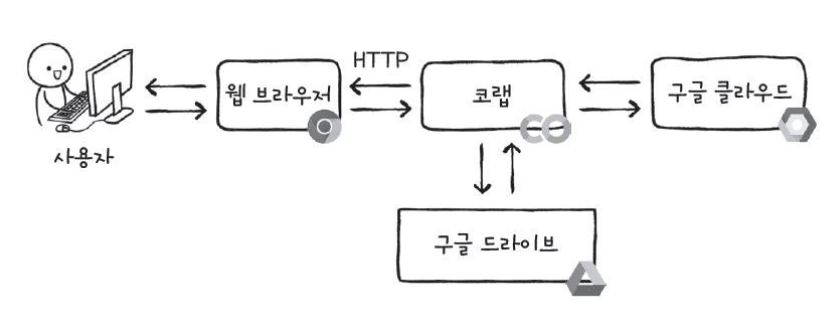
코랩을 이용하기 위해 아래 주소에 접속하면 된다.
Colaboratory에 오신 것을 환영합니다 - Colaboratory (google.com)
Google Colaboratory
colab.research.google.com
그렇다면 YOLO란 무엇일까?
욜로는 You Only Look Once의 약자로 Object detection 분야에서 유명한 모델이다.
즉, 딥러닝을 이용해서 객체를 탐지하는 모델이다.
욜로에도 YOLO, YOLOv2, YOLOv3, YOLOv4, YOLOv5 등 많은 모델이 존재하는데 이번에 사용해 볼 모델은 YOLOv3이다.
아래는 YOLOv3의 데모영상이다.
아래 영상을 본다면 욜로가 어떤 것인지 쉽게 이해될 것이다..
https://www.youtube.com/watch?v=MPU2HistivI
YOLO를 이용해 내 사진을 Object detection 해보자.
지금은 훈련된 모델을 테스트해보지만 프로젝트를 통해 최종적으로, 인식한 Object가
우리가 사전 입력한 Object와 동일한지 판단하는 단계까지 YOLO를 customizing 하고자 한다.
우리가 준비해야할 파일들이 있다.
Weight file : 훈련된 모델, Object detection 알고리즘의 핵심이다. (yolov3.weights)
Cfg file : 구성파일. 알고리즘에 관한 모든 설정이 있다. (yolov3.cfg)
Name files : 알고리즘이 감지할 수 있는 객체의 이름을 포함한다. (coco.names)
Sample 사진 : Object detection을 할 사진이다. (1.jpg 등 각자의 사진)
만약 customizing을 원한다면, cfg파일을 수정하거나 새로 만든 뒤 훈련 데이터로 모델을 학습시키면 된다. 그러면 weight파일이 새로 생성된다. 그리고 names파일에는 원하는 객체의 이름을 포함하면 된다.
파일들의 구성은 아래와 같다.
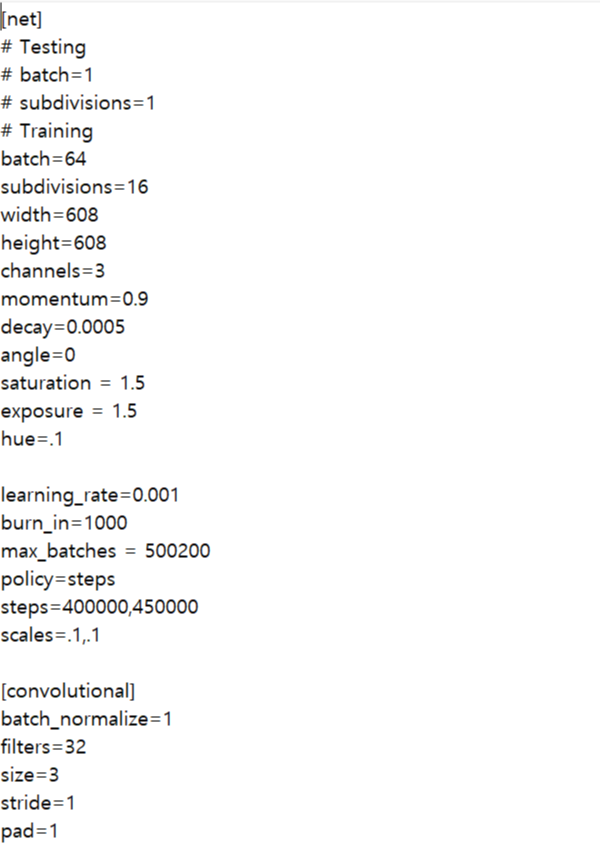

weight 파일은 아래의 사이트에서 다운받을 수 있다.
https://pjreddie.com/darknet/yolo/
YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev. Comparison to Other Detectors YOLOv3 is extremel
pjreddie.com
코랩을 이용한다면 content아래에 해당 파일들을 업로드 해주면 된다.
content아래에 있는 sample_data라는 폴더와 동등한 위치에 업로드 하자.
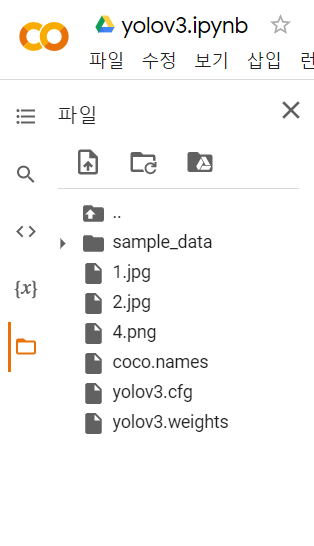
YOLO를 사용하기 위해서는 딥러닝 프레임워크가 필요하다.
이번에 사용할 프레임워크는 OpenCV (Open Source Computer Vision)로, 사진과 동영상 처리에 이용하는 오픈소스 라이브러리이다.
OpenCV 모듈을 컴퓨터에 설치해야하지만, 설치없이 사용을 하고자 Colab을 이용하고자 한다.
Colab에서 OpenCV와 numpy 모듈을 import 해주자.
import cv2
import numpy as np
그리고 위의 파일들을 이용해 YOLO 모델을 load해보자.
실행 환경에 따라 아래에서 두 번째 줄에서 index error가 날 수도 있다.
그럴 때는 output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()] 로 수정해주면 에러가 사라진다.
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
classes = []
with open("coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
colors = np.random.uniform(0, 255, size=(len(classes), 3))
Object detection 하기를 원하는 Sample 사진을 가져와보자.
img = cv2.imread("1.jpg")
img = cv2.resize(img, None, fx=0.4, fy=0.4)
height, width, channels = img.shape
Blob은 이미지 특징을 잡고, 크기를 조정하는데 사용한다. 여기서는 416 X 416 size로 조정하였다.
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
정보를 화면에 출력하는 코드이다.
confidence는 0에서 1까지 범위를 가지는 detection에 대한 confidence, 즉 신뢰도이다.
if confidence >0.5 : 라는 부분은, confidence가 0.5 이상이면 해당 Object라고 탐지하고,
그렇지 않으면 해당 Object가 아니라는 것을 의미한다. 이 숫자를 0.5에서 1에 가깝게 올리면 정확도가 높아진다.
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
객체를 탐지할 때, 같은 객체임에도 박스들이 여러개 생성될 수 있다. (박스란? 감지된 객체를 둘러싼 사각형)
박스 중복을 방지하기 위해 noise를 지워주는 과정이 필요하다.
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
imshow()함수를 이용해야한다.
imshow()는 원하는 크기의 행렬을 만들어서 원하는 색으로 채우는 함수이다.
하지만 코랩에서는 해당 함수를 사용할 수 없으므로 아래의 코드를 이용해 import를 해주자.
from google.colab.patches import cv2_imshow
아래에서 세 번째 줄에 cv_imshow()를 이용하였다.
실행 환경에 따라 코랩이 아니라면, 위 코드를 import하지 않고,
아래 코드의 밑에서 세 번째 줄을 cv2.imshow("Image", img) 로 사용하여 실행해도 된다.
Label은 the name of the object detected, 객체의 이름이다.
font = cv2.FONT_HERSHEY_PLAIN
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(classes[class_ids[i]])
color = colors[i]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
cv2.putText(img, label, (x, y + 30), font, 3, color, 3)
cv2_imshow(img)
cv2.waitKey(0)
cv2.destroyAllWindows()
1.jpg 사진에 대한 object detection 결과는 위와 같다.

다른 사진의 object detection 결과를 보자.
친구의 사진이다. (초상권은 허락을 구했다..)


Object Detection이 성공적으로 잘 되는 모습을 볼 수 있다.
names파일을 보면 알 수 있듯이 해당 모델은 shoe, shoes에 대한 훈련이 되지 않았다.
그래서 신발 사진 데이터를 넣어도 감지하지 못한다.
앞으로의 겨울방학과 22-1 학기 더 많은 공부를 통해, YOLO를 customizing하여 신발 객체를 탐지해낼 것이고,
우리가 사전 입력한 신발과 같은 제품의 신발인지 탐지하는 모델을 만들 예정이다.
추가적으로 결함도 분석과 챗봇에 대한 공부까지!! 파이팅!!
참고 사이트는 다음과 같다.
'CS > AI' 카테고리의 다른 글
| [딥러닝 입문] 4장 : 이진 분류 - 로지스틱 회귀 (0) | 2021.09.26 |
|---|---|
| [딥러닝 입문] 3장 : 선형 회귀, 경사 하강법 (+1장) (0) | 2021.09.19 |
| [딥러닝 입문] 2장 : numpy, matplotlib (0) | 2021.09.19 |

