[C++] 백준 알고리즘 1517번 버블 소트
문제 이름은 버블 소트지만 머지 소트 (병합 정렬)로 풀어야하는 문제. 왜냐하면 1 ≤ N ≤ 500,000 이기 때문에 n^2 으로 풀 수 없기 때문이다..
헷갈려서 정리를 해봤는데 병합만 늘 O(N*logN) 이고,
기수 정렬이 O(kN),
삽입, 선택, 버블 등 대부분의 정렬은 최악의 경우 O(N^2) 까지 갈 수 있다.
그래서 안정적으로 빠른 병합 정렬을 잘 알아두는 것이 좋다고 한다.
1초의 시간이 주어졌을 때 대부분
1,000,000 정도의 데이터는 O(kN), O(N*logN)
10,000 정도의 데이터는 O(N^2)
500 이하의 데이터는 O(N^3) 인 알고리즘이 사용 가능하다고 한다.
왜냐하면 1초에 주로 1억회의 연산이 가능한데
10,000의 경우 N^2이면 1억이 되기 때문에 위와 같은 결론이 도출될 수 있다.
각설하고,,, 이 문제의 데이터는 최대 500,000개 이다.
긍게 O(N*logN) 인 합병정렬을 사용했다.
병합정렬은 데이터를 특정 구간만큼 자르고 부분 구간에서 정렬을 하여 합쳐나가는 정렬이다.
강호동이.. 천하장사가 되는 것 보다
천하장사가 되는 방법을 설명하는게 더 어렵다고 했는데..
병합 정렬을 말로 하려니 힘들다..
(그렇다고 병합 정렬을 구현하는게 더 쉽다는건 아님..)
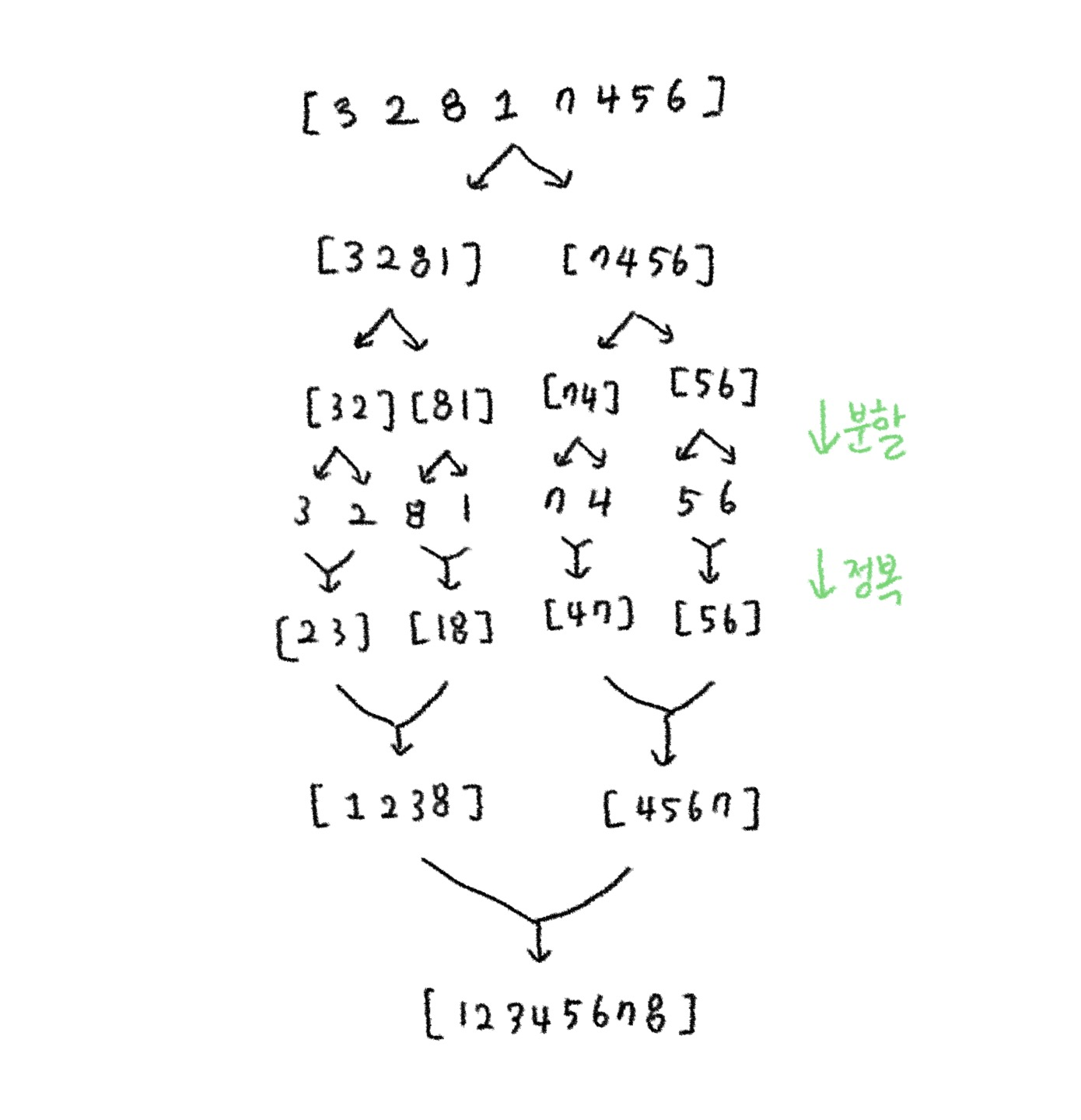
이러한 과정을 거쳐 정렬이 된다.
코드는 아래와 같다.
#include<iostream>
#include<vector>
using namespace std;
vector<int>v;
vector<int>temp;
long long result=0;
void merge_sort(int start, int end){ // 병합 정렬
if(end-start<1) return; // 분할이 완료되면 return
int mid=start+ (end-start)/2; // 중간 값 (분할을 위한)
merge_sort(start,mid); // 재귀 (구간 1)
merge_sort(mid+1,end); // 재귀 (구간 2)
for(int i=start; i<end+1; i++){ // 변수 임시 저장
temp[i]=v[i];
}
int idx=start; // 원래 벡터에, 정렬된 값을 차례대로 저장하기 위해 쓰이는 인덱스
int p1=start; // 구간 1의 시작
int p2=mid+1; // 구간 2의 시작
while(p1<=mid && p2<=end){ // 한 구간의 데이터가 끝날 때 까지 반복
if(temp[p1]<=temp[p2]){ // 더 작은 값 저장
v[idx]=temp[p1];
p1++;
idx++;
}
else{
v[idx]=temp[p2];
result+=(p2-idx); // 뒷 배열에서 숫자가 앞으로 오는 경우 (이전 인덱스 - 새 인덱스)
p2++;
idx++;
}
}
while(p1<=mid){ // 남은 데이터 저장
v[idx]=temp[p1];
p1++;
idx++;
}
while(p2<=end){ // 남은 데이터 저장
v[idx]=temp[p2];
p2++;
idx++;
}
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int n;
cin>>n;
v.assign(n,0);
temp.assign(n,0);
for(int i=0; i<n; i++){
cin>>v[i];
}
merge_sort(0,n-1);
cout<<result<<'\n';
}이 문제에서 고려해야하는 것은 몇 번 swap 되었는가다.
분할된 값을 정복해나가는 과정에서 swap이 되는데,
swap 횟수는 뒤(인덱스)에 있던 데이터가 앞(인덱스)으로 오는 횟수와 같다.
4 3 인 데이터가
3 4 로 정렬되었다면 1번 swap 된 것이고 (3이라는 값이 인덱스 하나 앞으로 왔으므로 swap=1)
3 2 1 의 경우 정렬을 하려면
->
인접한 3, 2 가 변경 되어서 2 3 1
(2라는 값이 인덱스 하나 앞으로 왔으므로 swap=1)
->
2 1 3
(1이라는 값이 인덱스 하나 앞으로 왔으므로 swap=1)
->
1 2 3
(1이라는 값이 인덱스 하나 앞으로 왔으므로 swap=1)
즉 3번이 swap 된 것이다.
여튼 그래서 앞 구간 인덱스를 가리키는 p1, 뒷 구간 인덱스를 가리키는 p2 가 있을 때,
p2 를 가리키는 값이 p1을 가리키는 값보다 작아서 앞으로 오는 경우를 카운트하면 된다!
그런데 계속 틀렸습니다가 나와서 고민했었는데,
while(p1<=mid && p2<=end){ // 한 구간의 데이터가 끝날 때 까지 반복
if(temp[p1]<=temp[p2]){
v[idx]=temp[p1];
p1++;
idx++;
}
else{
v[idx]=temp[p2];
result+=(p2-idx);
p2++;
idx++;
}
}위 코드 부분에서, if 문 안에 조건을 아래와 같이 설정했어서 틀렸었다..
if(temp[p1]<temp[p2]){
v[idx]=temp[p1];
p1++;
idx++;
}
왜 temp[p1]<=temp[p2] 로 해야하냐면,
값이 같으면 swap이 안되기 때문에,
swap이 되는 else 부분에 temp[p1]==temp[p2] 조건이 포함되면 안되기 때문이다.
if (temp[p1]<temp[p2]) 가 되면
else 부분에 temp[p1]==temp[p2] 조건이 포함됨!
그리고 틀릴 수 있는 부분은 result 의 범위가 int 를 벗어난다는 것과, temp 벡터 또한 v 벡터 처럼 n 크기로 assign 해야한다는 점!